Friday, 4 April 2025
Tuesday, 30 January 2024
Monday, 28 August 2023
Saturday, 26 August 2023
Retirement projects update
General tidying up:
1. Using Google Calendar as my day to day diary (plus Google Contacts as my main address book, and Google mail for more and more purposes).
- This is finally working adequately.
- Calendar integration with Outlook was hard.
- I ended up having to use a free Outlook plugin called CalDav Synchronizer. Outlook's OOTB 'integration' allows you to subscribe to a Google calendar (one way sync from Google to Outlook) but does not support two-way sync (doh).
- I still haven't got category colours synchronising properly for mail or calendar.
- Outlook won't support category colours at all for Google mail because it's accessed via IMAP. That means that the UI has no 'categorisation' elements present at all unless you really dig for them.
- I had to implement another free 3rd party solution (GO Contact Sync Mod) to synchronise contacts; Outlook doesn't support this at all OOTB.
- Getting distribution lists to synchronise and using them effectively, for which I find you have to use hidden category colours and spurious meeting drafts, is basically a magic trick (I shall write a blog post on this).
- Google mail's wacky lack of folders and realistic lack of any proper Archive function don't help at all. Why design it differently from every other email system on the planet? It's not as if it provided any fab new functionality (and Google's implementation of mail rules is a joke). Plus, Outlook hides Google mail items with no labels from view, presumably because IMAP can't see them.
- I have to say that the real problem with becoming more Google-centric is the support situation. When I think how much I have complained in the past about Microsoft Community, I am embarrassed. Google don't even pay lip service; their 'Help Communities' appear to be moribund and uncurated. (Having said which, Google Analytics does have a lively Discord channel with active and effective, if under-resourced, Google input, but I only found out about it by accident on Twitter.)
- Done, by paying Microsoft an extra approx. £3 a month, but since I have used it a total of once I am not sure why I bothered.
- Big success. Bye bye Dropbox, just too many annoyances.
- For less than my previous Dropbox subscription I can get Office 365 (including on the desktop), Teams (as above), and 1TB of OneDrive space.
- OneDrive integrates far better into Windows, e.g. you can set a folder to 'online only' automatically via PowerShell.
- It has effective support channels that don't assume you know nothing and/or that your question is daft.
- Plus, search in OneDrive is on another planet compared with Dropbox, which can't even see inside a .msg file, while OneDrive even indexes text on JPGs.
- And a shout out to the robocopy Low Disk Space Mode which allowed me to shift nearly 200GB of data from Dropbox to OneDrive fairly painlessly.
- Done (for my locally hosted databases, anyway) via mysqldump.
5. Tidy up my cpanel hosting environment (deletion of loads of ancient experiments, etc.)
- Done.
6. Sort out non-mySQL backups for my hosting (I have never yet found a fully usable solution for this)
- Sync'd via winscp, which is slow but does a far better job than FTP.
i-Community:
7. Transferring the website across to Meridian to look after.
- Done.
- End of an era ... I had been involved in i-Community, and its predecessor the Catalyst/Notability/Logicalis IT Forum, ever since the summer of 2000. Lots of nice messages from members remembering IT Forum and i-Community Rochester trips.
www.notamos.co.uk:
8. Updating Google Analytics usage to use their new offering.
- Done. I shall be publishing a specific blogpost on this. (To say that Google don't make it easy is an understatement.)
Thursday, 20 April 2023
Retirement Projects
I've now retired from active customer work (on 30th March), but still have a fair few techie projects on the go, so I thought I would document them here.
General tidying up:
- Using Google Calendar as my day to day diary
- Regaining access to Teams
- Moving my cloud storage from Dropbox to OneDrive
- Digitising a lot of family photographs
- Audio and video
- Using Visual Studio and Azure DevOps properly
- Cleaning up various horrible scripting mechanisms to use PowerShell
- Automation of mySQL backups
- Tidy up my cpanel hosting environment (deletion of loads of ancient experiments, etc.)
- Sort out non-mySQL backups for my hosting (I have never yet found a fully usable solution for this)
i-Community:
- Transferring the website across to Meridian to look after
www.notamos.co.uk:
- Updating Google Analytics usage to use their new offering
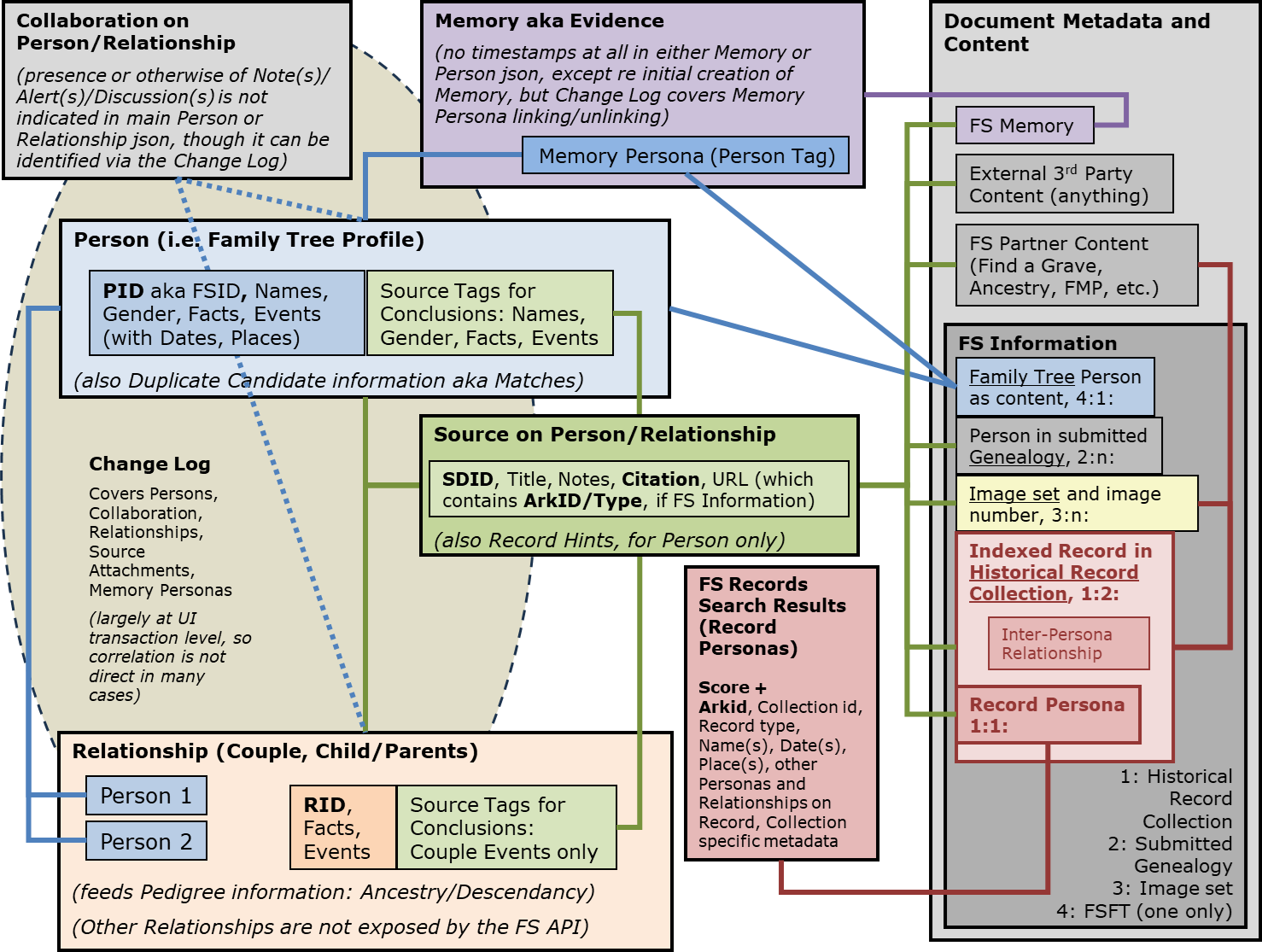
Genealogy:
- Various proposals concerning research and data quality aids (a lot of thinking and discussion still needed here)
Saturday, 26 May 2018
Thoughts on StackOverflow
I've been having an interesting time lately engaging with the StackOverflow community at https://stackoverflow.com/.
I got involved because I had found lots of useful code on there when rewriting notamos.co.uk, and thought I should try to give something back.
It's been a mixed experience, mainly because I expected it to work like Microsoft Community, an environment with which I am very familiar from past Windows Phone forum involvement; wrong, because StackOverflow is explicitly aimed at building a knowledge base rather than at helping people work through problems. On StackOverflow you are supposed to ask an intelligent question, get an intelligent answer, and move on, with discussion/teaching discouraged (though by no means absent in practice).
The most assumption-challenging question I have encountered is (almost literally) 'I have written a complex Java-based web application, I want to put it live, what server should I put it on?'. But, far worse, so many developers appear never to have been taught exception handling, problem determination, basic relational database design, web application security, or even how to articulate a problem clearly. No wonder (to reiterate a regular rant) there is so much bad production software out there.
I got involved because I had found lots of useful code on there when rewriting notamos.co.uk, and thought I should try to give something back.
It's been a mixed experience, mainly because I expected it to work like Microsoft Community, an environment with which I am very familiar from past Windows Phone forum involvement; wrong, because StackOverflow is explicitly aimed at building a knowledge base rather than at helping people work through problems. On StackOverflow you are supposed to ask an intelligent question, get an intelligent answer, and move on, with discussion/teaching discouraged (though by no means absent in practice).
The most assumption-challenging question I have encountered is (almost literally) 'I have written a complex Java-based web application, I want to put it live, what server should I put it on?'. But, far worse, so many developers appear never to have been taught exception handling, problem determination, basic relational database design, web application security, or even how to articulate a problem clearly. No wonder (to reiterate a regular rant) there is so much bad production software out there.
Sunday, 4 February 2018
Using Blogger as a source of website content

I put together a basic website using what I knew, which was html and shtml, and I created and maintained all the content (about 250 entries altogether) using that well known development tool Notepad.
Now it is time to hand the task over to others.
I realised a while ago that I had to find a better method of content editing, for speed, accuracy, and consistency, and also so that I could share the load with others with less technical skills.
Most of the entries are very short; a lot of them involve images; and many contain links to uploaded PDFs. Entries usually start off as 'highlights', linked to from the home page and notified to members via email and Twitter. Over time they lose their 'highlight' status; finally they are moved to the archive page.
I had a play with MODX, which we use for the i-Community website, but it's really far too complicated for the purpose (it's unnecessarily complicated for i-Community, really).
I had spent a bit of time in late 2017 learning some PHP (forced into it by the sudden demise of the Twitter feed mechanism on the i-Community home page) and a bit of Javascript (in order to implement an urgently needed non-Flash MP3 player for www.notamos.co.uk).
It occurred to me that I might solve the content editing problem via a Blogger blog like this one, pulling the content into the website via the RSS feed that is automatically provided for any Blogger blog.
Here's an example blog post (for a 'highlight'):


And here's the link on the home page:
The basics turned out to be pretty easy to do, using an open source tool called Feed2JS. This uses a second open source tool, Magpie, to read the RSS feed; the shipped version of Feed2JS, as the name suggests, then exposes the content via Javascript, with various formatting options.
I separated the content into the many necessary categories (News 'highlight', older News, News archive, Local Events, etc.) using Blogger's tags called Labels (each of which is available as an individual RSS feed), and automated the generation of the Feed2JS scripts (one per content category) via batch files.
So far so good.
The three remaining problems were: migrating all the existing content; implementing the 'highlight' links on the home page; and automating the 'last amended' date on each page.
Here's an example (containing 2 entries) of the xml import.
I eventually used two much simplified copies of the Feed2JS code, with no Javascript; en route I took a considerable liking to PHP - a very friendly and easily learned language, it seems to me (I particularly admire the array handling).
The only remaining problem was the need to wait for Magpie's hour-long cache period to elapse before blog changes were reflected on the main website. In practice we just wait, although occasionally I do set the cache period to 1 minute temporarily (which has pretty awful effects on website performance, which is usually acceptable, if not as fast as the pre-blog version).
Finally I created a couple of little PHP utilities permitting the upload of PDFs and full size images to the website without FTP. (I subsequently had problems with these being used for malware purposes, which I should have anticipated - I have now moved them into a password-protected directory.)
Anyway it's all had the required effect: editing is now much easier, and my colleagues are happy to share the load.
Subscribe to:
Posts (Atom)
